In the previous note, we concluded that byte-level models were not a good fit for clinical text classification. ByT5-small scored 0.15 F1 on our benchmark, close to random. CANINE-S performed poorly on minority classes. From those results, we drew a broader conclusion: that without domain-specific pretraining signal, working at the byte level offered no real advantage.
We now think that conclusion was overgeneralised. The weak performance we observed may have been a property of those particular models and our adaptation strategy, rather than of byte-level processing in general. ByT5 and CANINE were trained on general multilingual corpora using architectures that scale poorly to long sequences. Meta’s Byte Latent Transformer (BLT) takes a different approach: a 1B-parameter model that dynamically patches bytes based on entropy. In principle, this combines byte-level robustness with transformer-scale representations while keeping inference cost sub-quadratic.
There is a complication. BLT was released as a generative language model, with no classification head and no published fine-tuning recipes. We could not find prior work on adapting BLT for downstream classification, nor on continued pretraining for a specific domain. This note describes our own attempt at the former, with the latter to follow.
The Architecture
BLT processes text in three stages. A local encoder groups bytes into variable-length patches under a learned entropy model. A global transformer reasons over those patches. A local decoder reconstructs bytes for generation. For classification, the decoder is unnecessary. What we want is the global transformer’s output, pooled into a single representation vector.
{ }class BLTForSequenceClassification(nn.Module):
def __init__(self, blt_components, num_classes, pooling="attention"):
super().__init__()
self.blt = blt_components.model
self.pooler = build_pooler(pooling, dim=2048)
self.classifier = nn.Linear(2048, num_classes)
self._hook_output = None
self.blt.global_transformer.register_forward_hook(self._capture)
def _capture(self, module, input, output):
self._hook_output = output
def forward(self, input_ids, **kwargs):
self.blt(input_ids, **kwargs) # run BLT, ignore generative output
patches = self._hook_output # (batch, num_patches, 2048)
pooled = self.pooler(patches) # (batch, 2048)
return self.classifier(pooled) # (batch, num_classes)The global transformer produces patch representations of dimension 2048. We pool them with learned attention (a single query head over all patches), then apply a linear classifier. The choice of pooling appeared to matter in our runs. Attention pooling lets the model assign weight to specific patches, which is plausibly useful given that BLT’s patch boundaries are entropy-driven: high-entropy patches (rare words, jargon, abbreviations) may carry more discriminative signal than low-entropy filler. Mean pooling, by contrast, treats all patches equally.
We compared four pooling strategies: attention, mean, last-patch, and max. Attention pooling produced the highest validation accuracy in every configuration we tested. We have not yet quantified the gap across multiple seeds, so we report this as an observation rather than a robust finding. We use attention pooling for the rest of this work.
Training in Phases
With 1B frozen parameters underneath, training requires some structure. We use two phases, each designed to test a separate hypothesis.
Phase 1, the linear probe. Freeze all of BLT, train only the attention pooler and classifier head (~16.8M parameters). This phase tests whether BLT’s pretrained patch representations already encode information useful for classification. Strong probe performance would suggest the representations are usable as-is. Weak probe performance would indicate the generative pretraining objective produced features that do not transfer well to discrimination.
Phase 1.5, LoRA. Keep base weights frozen but inject low-rank adapters into the global transformer’s attention layers (~20M trainable parameters, around 2% of the full model). This phase tests whether we can adjust the representations toward better class separation without disturbing the underlying pretrained weights.
LoRA Sweep
We swept rank, target modules, and learning rate on SST-2. Search space: ranks [8, 16, 32], target modules [wq+wv vs. wq+wk+wv+wo], learning rates [1e-4, 2e-4]. The intended grid contained twelve configurations. Higher-rank configurations combined with all four target modules ran out of memory on our Volta GPU and were not evaluated.
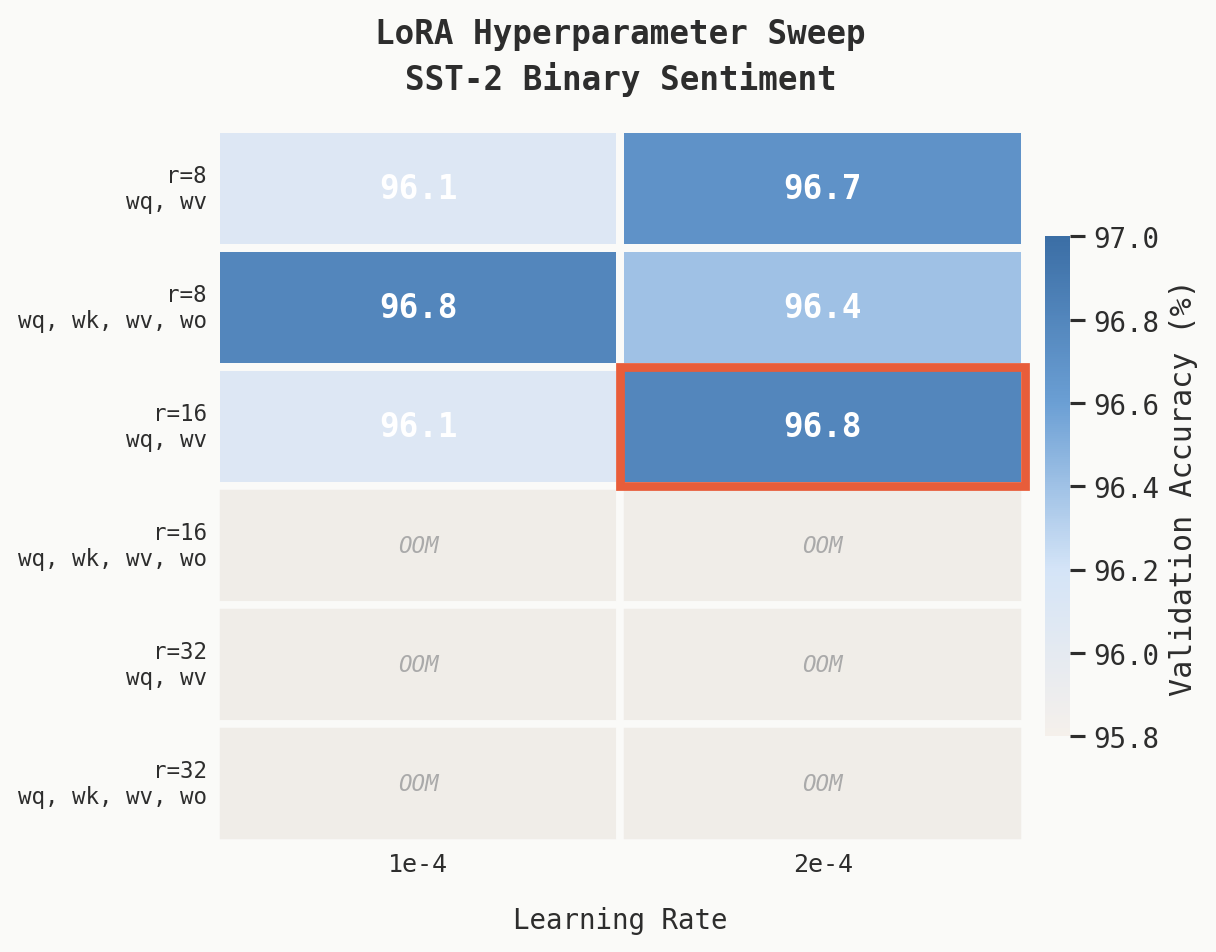
| Rank | Targets | LR | Val Accuracy | Val Loss |
|---|---|---|---|---|
| 8 | wq, wv | 1e-4 | 96.1% | 0.129 |
| 8 | wq, wv | 2e-4 | 96.7% | 0.134 |
| 8 | wq, wk, wv, wo | 1e-4 | 96.8% | 0.119 |
| 8 | wq, wk, wv, wo | 2e-4 | 96.4% | 0.119 |
| 16 | wq, wv | 1e-4 | 96.1% | 0.124 |
| 16 | wq, wv | 2e-4 | 96.8% | 0.116 |
Within the configurations we ran, the best validation accuracy (96.8%) was achieved by two settings: rank-16 with wq+wv targets, and rank-8 with all four targets. The rank-16 wq+wv setting produced a slightly lower validation loss (0.116 vs 0.119), which we tentatively read as a marginally better fit. The difference is small and rests on a single seed, so we report the choice as a working selection rather than a definitive conclusion. We adopted it for the main experiments. We did not observe a clear benefit from adding key and output projections at rank 8 in our runs.
One pattern in these results may or may not generalise. The narrower-target, higher-rank configuration (r=16, wq+wv) slightly outperformed the wider-target, lower-rank one (r=8, all four). One possible interpretation is that, for BLT, additional adaptation capacity in the query/value pathway is more useful than spreading the same parameter budget across all four attention projections. We are wary of drawing strong conclusions from a single dataset and seed. We treat this as a hypothesis to test on harder tasks.
Results vs. Baselines
We report headline numbers for SST-2 binary sentiment, single seed (42). These should be read as preliminary; multi-seed and multi-dataset evaluations are in progress.
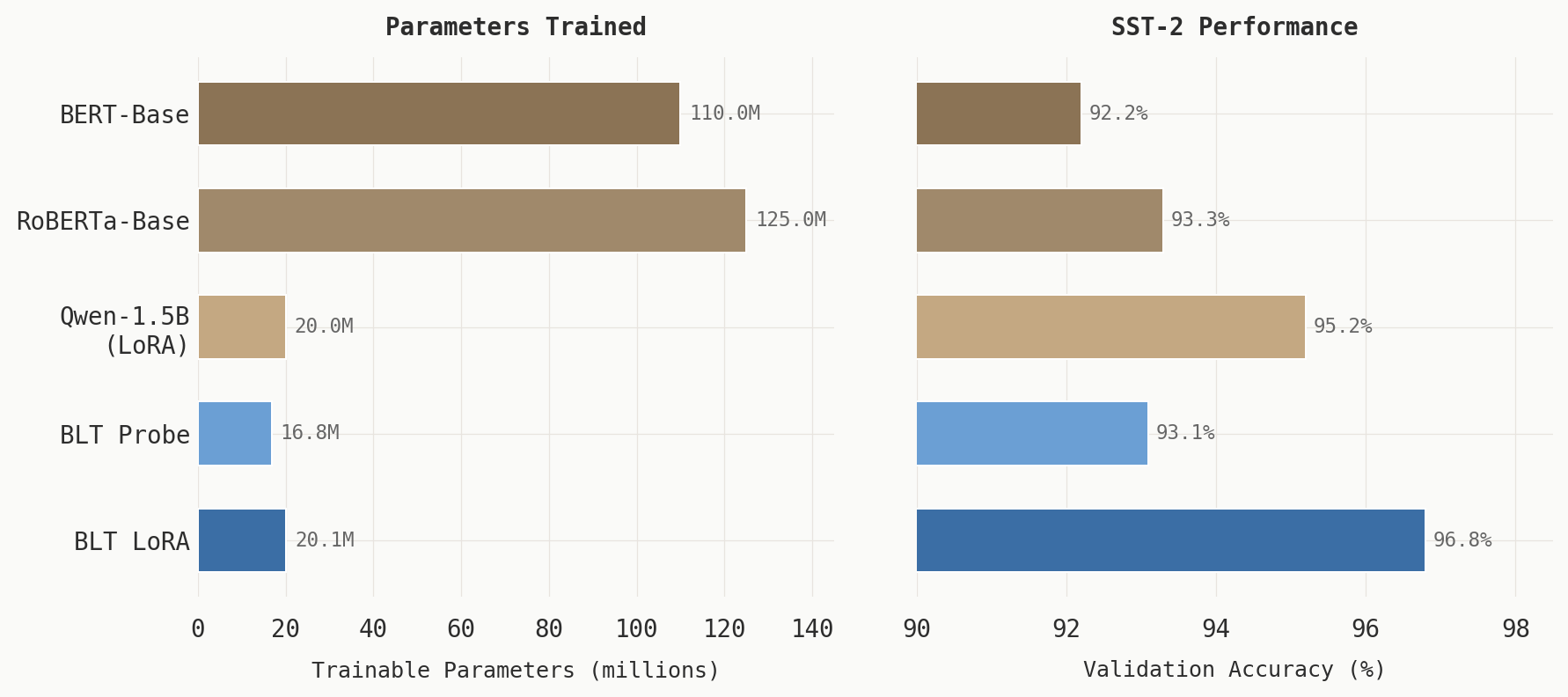
| Model | Params (trainable) | Accuracy | Training Time |
|---|---|---|---|
| BERT-Base | 110M (all) | 92.2% | 16 min |
| RoBERTa-Base | 125M (all) | 93.3% | ~16 min |
| Qwen-1.5B | 1.5B (LoRA) | 95.2% | ~45 min |
| BLT Phase 1 (probe) | 16.8M | 93.1% | ~5 min |
| BLT Phase 1.5 (LoRA) | 20.1M | 96.8% | ~2.4 hr |
In this single run, the linear probe (Phase 1) reached accuracy comparable to fully fine-tuned RoBERTa-Base while training only 16.8M parameters in roughly five minutes. Read narrowly, this is consistent with BLT’s pretrained patch representations encoding information useful for binary sentiment classification. The broader claim, that BLT representations transfer well to classification in general, would require evaluation across more tasks, datasets, and seeds before we’d be willing to make it.
With LoRA applied, BLT reached 96.8% on this run, above the encoder baselines we tested and on par with Qwen-1.5B at substantially fewer trainable parameters. The comparison to Qwen warrants caveats. Qwen is a 1.5B decoder-only LLM with LoRA applied to its attention layers, and we have not controlled for differences in pretraining data, training duration, or LoRA configuration between the two. The numbers are suggestive of parameter-efficient adaptation working well for BLT on this task, but they are not a clean apples-to-apples comparison.
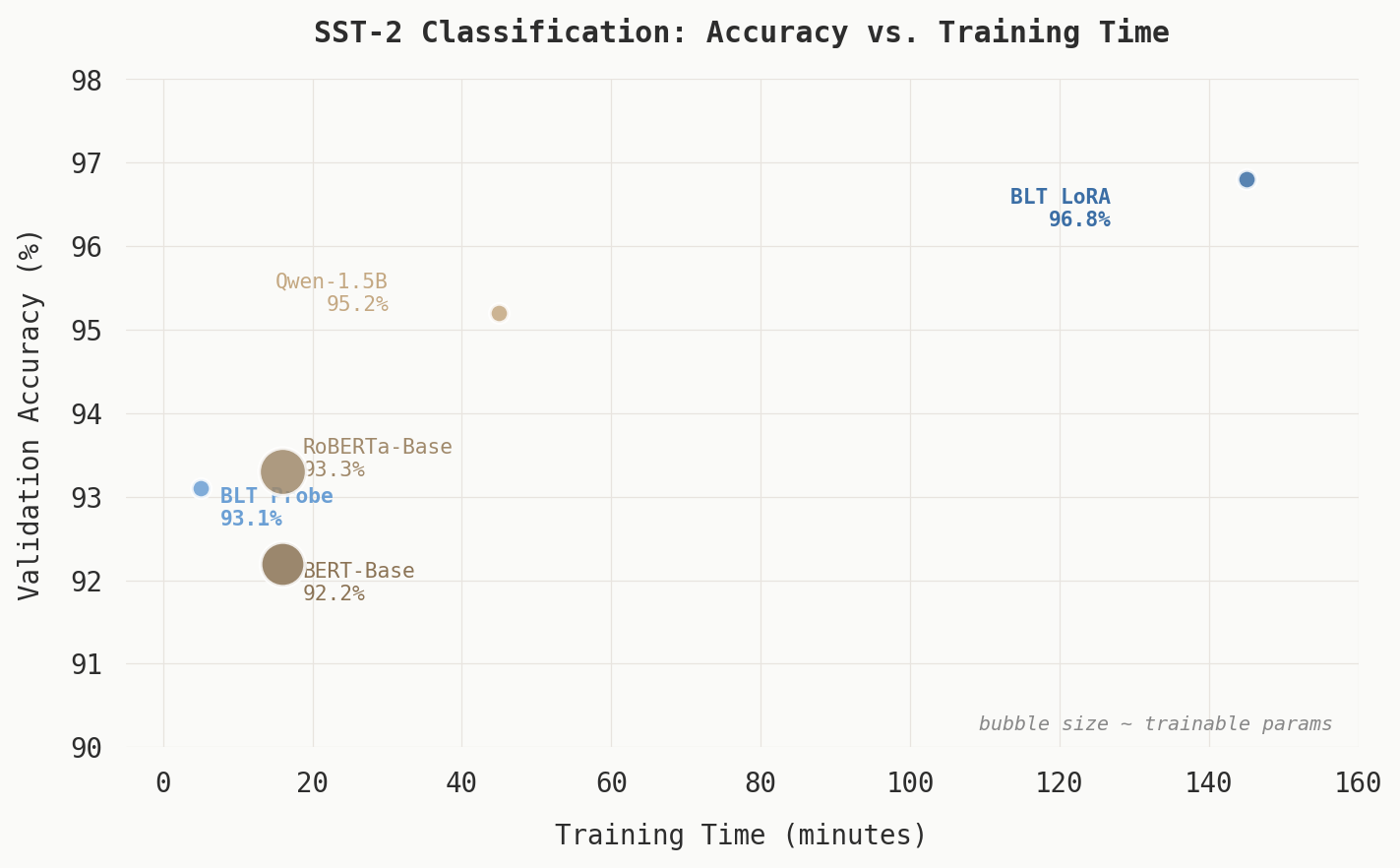
The cost is wall-clock time. BLT’s byte-level processing combined with the 1B backbone makes forward passes expensive. LoRA training on SST-2 took approximately 2.4 hours, against approximately 16 minutes for BERT-Base on the same hardware (Quadro GV100, 32GB). Per-step throughput is lower for BLT, even though we are optimising fewer parameters. Whether this trade-off is acceptable depends on whether the binding constraint in a given workflow is engineer time, GPU time, or final accuracy.
And About Noise
The hypothesis motivating this whole line of work is that byte-level models should be more robust to character-level noise than tokenizer-based models, because they do not rely on a fixed vocabulary. When BERT encounters a typo such as “pnuemonia”, the WordPiece tokenizer fragments it into unfamiliar subwords, and the resulting representation is unlikely to resemble the clean version. A byte-level model, in principle, sees only a slightly different byte sequence flowing through the same machinery; patch boundaries may shift, but no part of the input is lost to out-of-vocabulary handling.
We are running noise robustness evaluations now: random character substitution, insertion, deletion, and adjacent swaps at 10%, 20%, and 30% perturbation rates. Noise is applied at test time only; models are trained on clean data. This setup is intended to isolate intrinsic robustness from learned recovery.
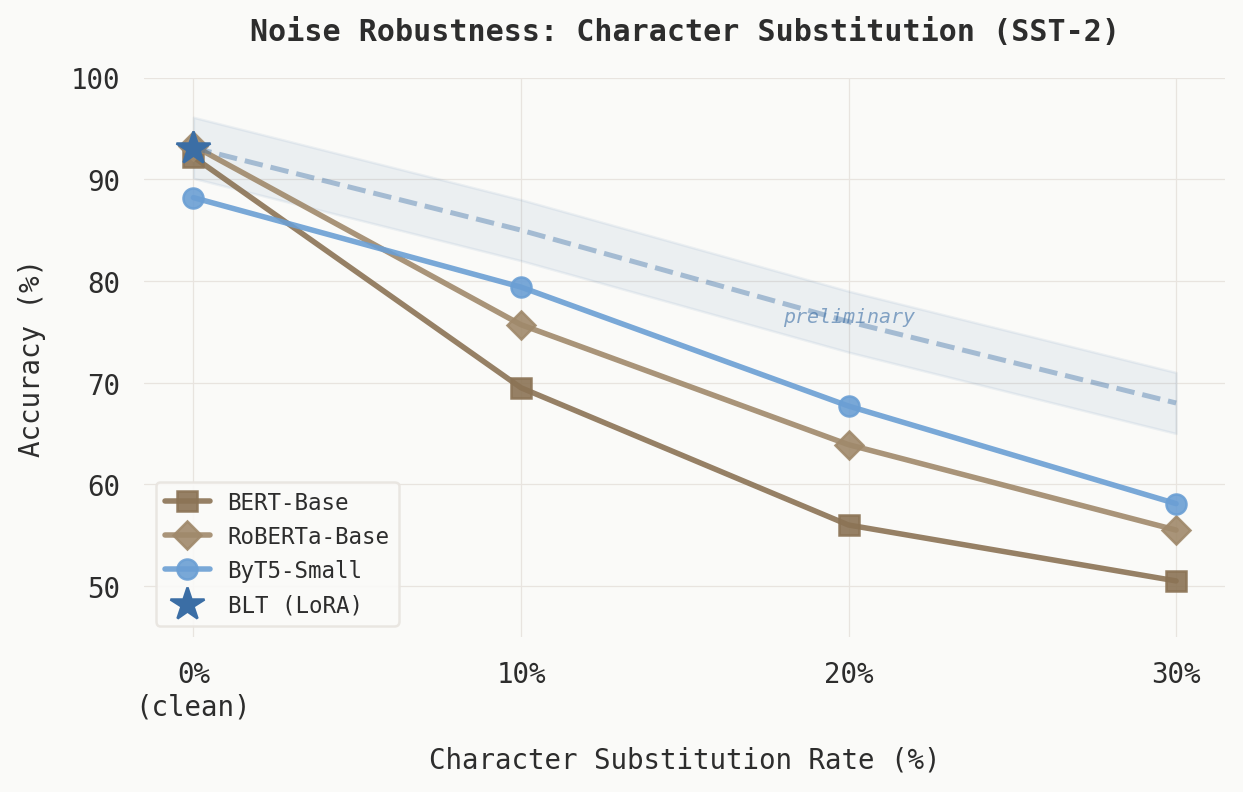
Preliminary results, under 10% random character substitution:
- BERT-Base: 92.2% to 69.5% (drop of 22.7 points)
- RoBERTa-Base: 93.3% to 75.7% (drop of 17.6 points)
- ByT5-Small: 88.2% to 79.4% (drop of 8.8 points)
In these runs, ByT5 lost less than half as much accuracy as BERT under the same perturbation. This is consistent with the byte-level hypothesis on this single noise type at one perturbation rate. We have not yet evaluated BLT under the same conditions. Whether BLT’s degradation will be smaller than ByT5’s, comparable, or worse is currently a prediction we have not tested.
Full noise robustness numbers, including clinically realistic perturbations such as abbreviation expansion, casing loss, and PHI-mask insertion, will appear in the next note. We are also examining whether BLT’s patch boundaries remain stable under noise. Initial inspection suggests they shift, which would have implications for how the model handles perturbed inputs and is worth investigating in its own right.
What’s Next
The SST-2 results are consistent with the architecture being viable for classification, but they are not on their own sufficient to support strong claims. Three pieces of evidence are needed to firm up the picture:
- Multi-dataset evaluation. AG News (4-class), SMS Spam (short text), and Tweet Sentiment (informal text) will indicate whether the SST-2 pattern extends beyond binary sentiment on edited text.
- Multi-seed confidence intervals. Five seeds (42, 123, 456, 789, 1024) across all models and datasets, to distinguish real differences from run-to-run variance.
- Full noise robustness benchmarks. Seven noise types at three perturbation rates across all models. This is the central hypothesis of the work, and the SST-2 numbers do not test it.
The longer-term experiment is continued pretraining on medical text. We plan to train BLT on clinical notes from MIMIC-III and PubMed abstracts before fine-tuning for classification. The motivation is that byte-level robustness, combined with clinical domain knowledge, might produce a model that handles real-world clinical text including its typos and inconsistent formatting. We frame this as a hypothesis. Whether continued pretraining helps, hurts, or has little effect on noise robustness in this setting is itself an open question.
The gap our previous benchmark identified was that domain-pretrained encoders are accurate on clean text but fragile under noise, while general byte-level models tolerate noise but lack domain knowledge. BLT with clinical continued pretraining is one possible way to address both. We have not yet shown that it does.
Code and experiment infrastructure at BLT-Experiments. This work builds on Meta’s BLT paper and follows up on our LLM vs. BERT benchmark.